Local Deployment of DeepSeek
Why Use a Local Large Model
The DeepSeek official website has been extremely popular recently and often fails to respond
Local deployment offers higher security
Local deployment can bypass some official restrictions
Test Environment
OS: Windows 10 Pro 22H2
CPU: AMD Ryzen 5 5600H (6C12T, Base 3.3GHz / Boost 4.2GHz)
GPU: NVIDIA GeForce RTX 3050 Ti Laptop GPU (4GB GDDR6 VRAM)
RAM: SAMSUNG 16GB DDR4-3200
IDE: LM Studio v0.3.9
Deployment Method
It is recommended to use an international network environment and enable TUN mode in your proxy tool
Download and install the LM Studio client
Click to goChange the model download directory (recommended)
This prevents models from consuming too much space on the C drive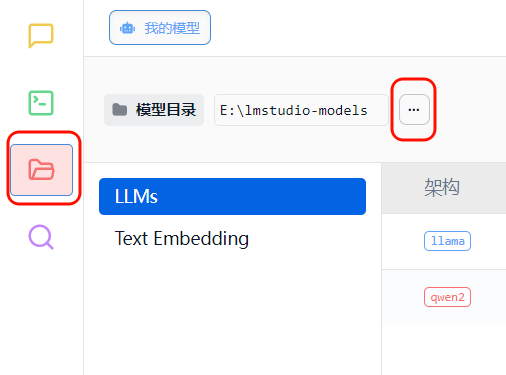
Download the appropriate model based on your computer configuration
Models withDistillin the name are distilled models
The recommended model isDeepSeek-R1-Distill-Llama-8B-Abliterated-GGUF, which runs smoothly with 4GB of VRAM. This model also removes some of DeepSeek's built-in restrictions, allowing more freedom in local use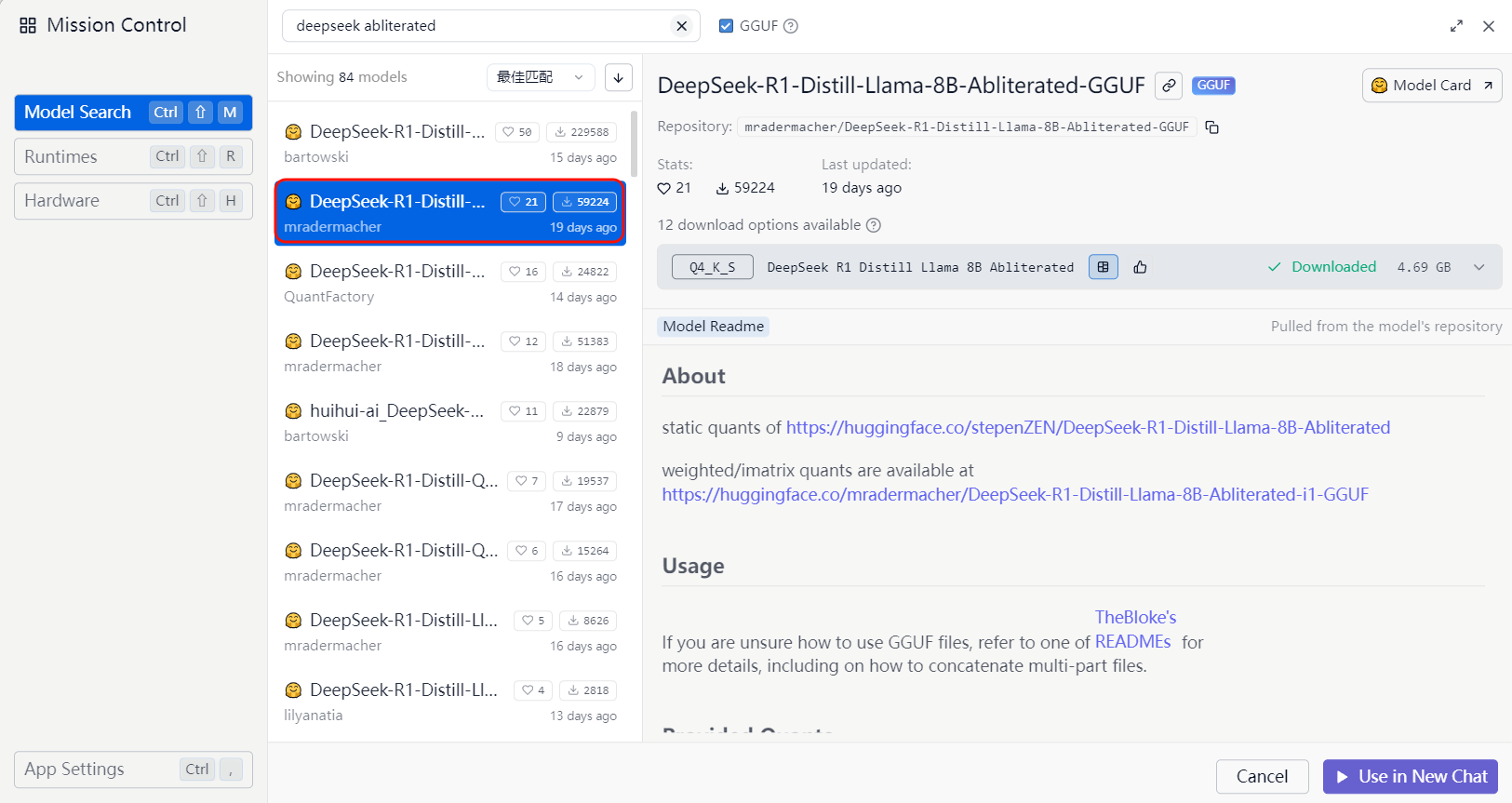
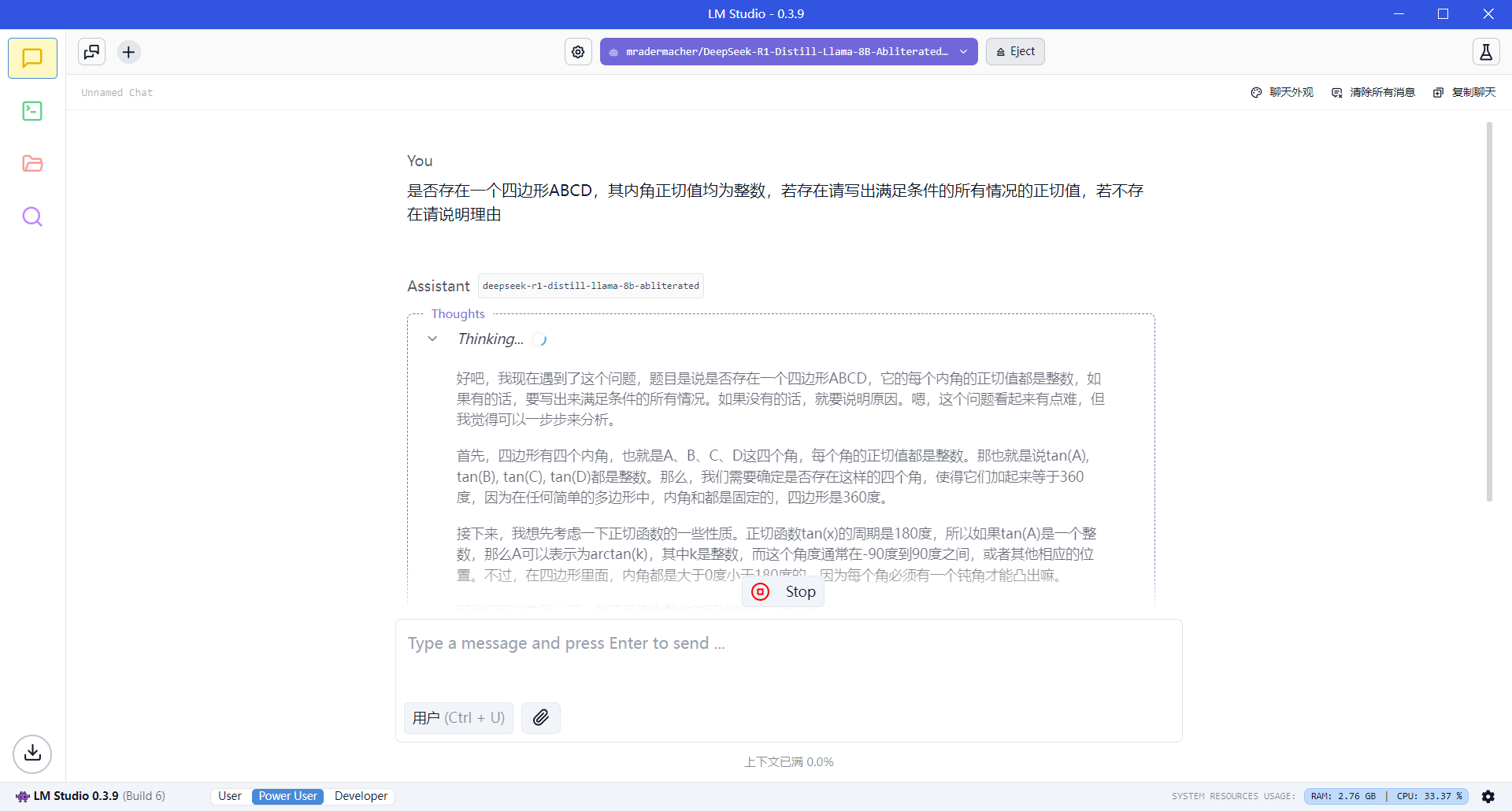
Load the model
After the download completes, click the top bar to load the model you just downloaded
It is recommended to increaseGPU Offloadand enableFast Attentionfor better performance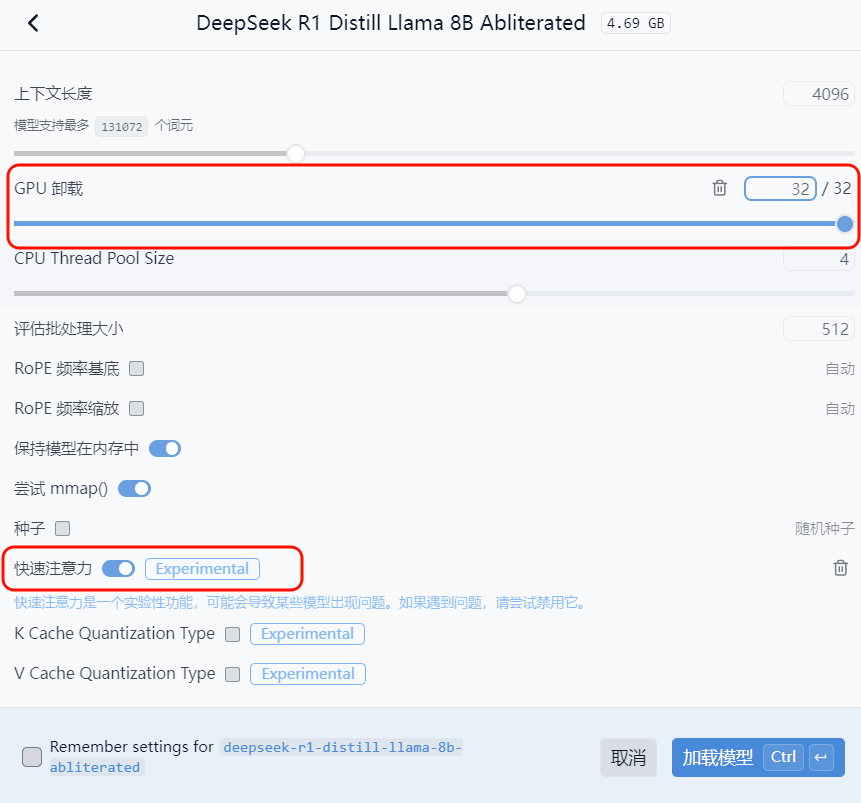
Start using it